

Architecture Overview#
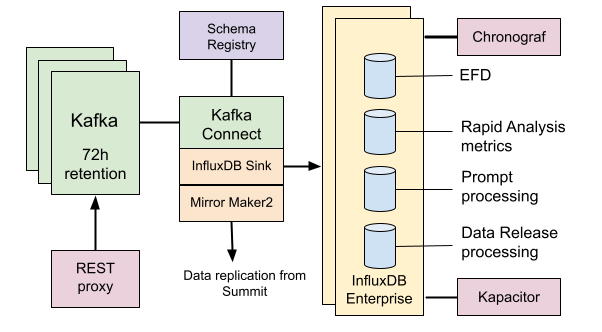
Kafka#
In Sasquatch, Kafka is used as a message queue to InfluxDB and for data replication between Sasquatch Environments.
Kafka is managed by Strimzi. In addition to the Strimzi components, Sasquatch uses the Confluent Schema Registry and the Confluent Kafka REST proxy to connect HTTP-based clients with Kafka.
Kafka Connect#
In Sasquatch, Kafka connectors are managed by the kafka-connect-manager tool.
The InfluxDB Sink connector consumes Kafka topics, converts the records to the InfluxDB line protocol, and writes them to an InfluxDB database. Sasquatch Namespaces map to InfluxDB databases.
The MirrorMaker 2 source connector is used for data replication.
InfluxDB Enterprise#
InfluxDB is a time series database optimized for efficient storage and analysis of time series data.
InfluxDB organizes the data in measurements, fields, and tags. In Sasquatch, Kafka topics (telemetry topics and metrics) map to InfluxDB measurements.
InfluxDB provides an SQL-like query language called InfluxQL and a more powerful data scripting language called Flux. Both languages can be used in Chronograf for data exploration and visualization.
Read more about the Sasquatch architecture in SQR-068.